搜索引擎工作原理
搜索引擎工作原理:如何让Google“爱”上你?
我们每天都在用Google,但它到底是如何在0.1秒内,从亿万网页中,找到我们想要的那个答案的?
把互联网想象成一个无边无际的巨大图书馆,而Google就是唯一的、全知全能的图书管理员。
这个管理员的工作,可以分为四个步骤:抓取、索引、排名、以及最终的个性化微调。
我们的所有SEO工作,本质上都是在用行动,以一种清晰、有逻辑的方式,向这位图书管理员证明:
“我的这本书,值得被你发现,值得被你收藏,更值得被你推荐给所有需要它的读者。”
第一步:抓取 (Crawling) - 发现你的网站
管理员做的第一件事,是派出无数个名为“爬虫”或“蜘蛛”的微型机器人。
这些“蜘蛛”永不停歇地在图书馆里穿梭,它们的工作很简单:从一本已知的书出发,顺着书里的参考文献(链接),去发现新的、未被收藏的书(网页)。
我们能做什么来帮助“蜘蛛”?
提交站点地图 (Sitemap): 主动给管理员一份我们图书馆的“藏书目录”,告诉他我们所有的藏书位置。
建立外链 (Backlinks): 当其他“名著”(权威网站)引用了你的书,就等于给蜘蛛搭了一座直达的桥。这是蜘蛛发现新书最主要的方式。
设置路标 (robots.txt): 在“员工休息室”的门上挂一个“闲人免进”的牌子,告诉蜘蛛哪些页面是我们的非公开区域,不需要它进去。
第二步:索引 (Indexing) - 理解并存入大脑
“蜘蛛”把发现的书带回来后,管理员并不会直接把它们扔上书架。
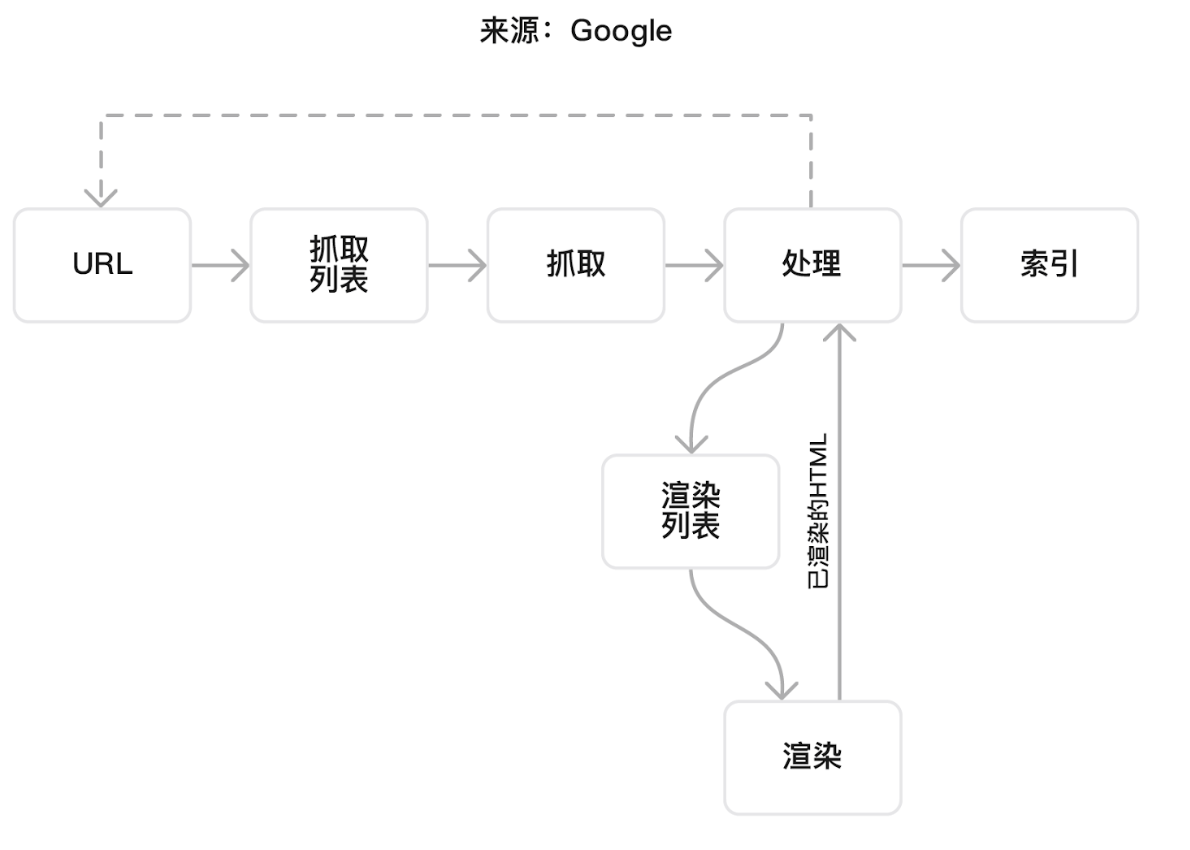
他会先仔细阅读、处理和分析这些书的内容,提取出关键信息(比如标题、文字、图片、链接等),然后贴上标签,分门别类地存入他那巨大无比的“大脑”——也就是搜索索引 (Search Index)。
这个索引,就是一个包含了全世界网页信息的数字图书馆。只有被存入这个索引的网页,才有机会在未来的搜索中被用户看到。
如果你的网站没有被索引,那它就相当于在互联网上“隐身”了。
第三步:排名 (Ranking) - 选出最佳答案
这是最关键,也是最复杂的一步。
当一个读者前来,问管理员:“我想找关于‘如何选购冰箱’的书”
管理员会立刻在他的“大脑”中,找出所有与“冰箱”相关的书籍。但他会通过一个极其复杂的“排名算法”,综合判断所有书的优劣,然后给出一个他认为最完美的推荐顺序。
但他该把哪一本最先推荐给读者呢?
他会通过一个极其复杂的“搜索算法” (Search Algorithm),像一个经验丰富的大侦探一样,综合判断所有书籍的优劣,然后给出一个他认为最完美的推荐顺序。
这个算法考虑的因素有数百个,但最重要的,无外乎以下几点:
- 权威性 (Authority) - 看“推荐度”: 这本书有没有被其他权威书籍引用过?也就是我们反复强调的外链。来自其他重要网站的链接,是Google判断你权威性的最重要信号之一。
相关性 (Relevance) - 看“匹配度”: 这本书的内容,是否完美地回答了读者的问题?算法会检查书名、章节标题(也就是你的H1/H2标签)里,是否包含了读者的提问。同时,它还会看书里有没有相关的图片、视频、数据等其他内容,来判断你的答案是否足够全面。(关键词与内容质量)
内容新鲜度 (Freshness): 这本书是昨天刚出版的,还是二十年前的?对于某些有时效性的问题,比如“今日新闻”,算法会优先推荐最新出版的书籍。
用户体验 (User Experience): 管理员会观察,之前的读者拿到这本书后,是满意地读了很久,还是立刻就扔到了一边?Google会参考类似的用户行为信号,来判断你的网站是否受用户欢迎。
第四步:个性化微调 (Personalization) - 为你打造的专属书单
在给出最终推荐之前,这位顶级的管理员还会做一件“贴心”的小事:他会根据对“你”的了解,对书单进行微调。
这有点像短视频的算法推荐,让搜索结果更具针对性。
根据你的地理位置
根据你的历史行为
根据你的语言偏好: 他会用你最熟悉的语言和你交流。如果你一直用中文提问,他会优先为你推荐中文版或翻译精良的著作(所以如果是做出海,最好单独配一个默认英文的搜索引擎)
最终结论:
理解了抓取、索引、排名、个性化这四大步骤,你就理解了SEO的全部核心。它能帮助我们更好地理解,为什么有时候你和你的海外朋友,在Google上搜索同一个词,却看到了不完全一样的结果。
我们的优化工作,就是要确保在所有这些环节中,都表现得尽善尽尽美。